
GAN 在半监督学习中的应用
概述
在[4]中介绍了一个半监督问题[2],考虑一个分类问题,如果训练集中大部分样本没有标记类别,只有少部分样本有标记。则需要用半监督学习(semi-supervised)方法来训练一个分类器。wiki上的这张图很好地说明了无标记样本在半监督学习中发挥作用:
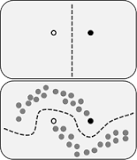
如果只考虑有标记样本(黑白点),纯粹使用监督学习。则得到垂直的分类面。考虑了无标记样本(灰色点)之后,我们对样本的整体分布有了进一步认识,能够得到新的、更准确的分类面。
核心概念
在半监督学习中运用GAN的逻辑如下。
- 无标记样本没有类别信息,无法训练分类器;
- 引入GAN后,其中生成器(Generator)可以从随机信号生成伪样本;
- 相比之下,原有的无标记样本拥有了人造类别:真。可以和伪样本一起训练分类器
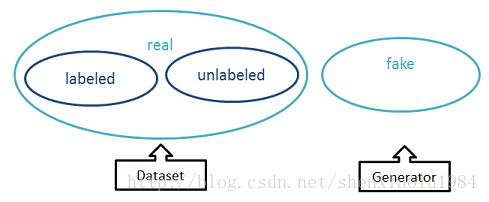
原理介绍
参考原博文[4],也有文章代码的是实现,当然该模型的当数据都是有标签的时候,该模型就退化为了监督模型,就是看出一个多分类问题。
GAN 在监督学习中的应用
概述
在[5,6]中介绍了一个监督问题,考虑的是一个语音分割的问题[3,7]。原作者所提出的网络框架包含了一个生成模型就是图中的Segmentor,该Segmentor主要的作用是负责真实标签图的预测,而且使得预测的标签图可以迷惑到判别器。判别器就是途中的Adversarial network(对抗网络),用于区分输入是真实的标签图和预测出来的从Segmenotor生成的概率图,引入对抗网络的目的是使得得到的概率预测图更符合真实的标签图,具体的网络结构如下,
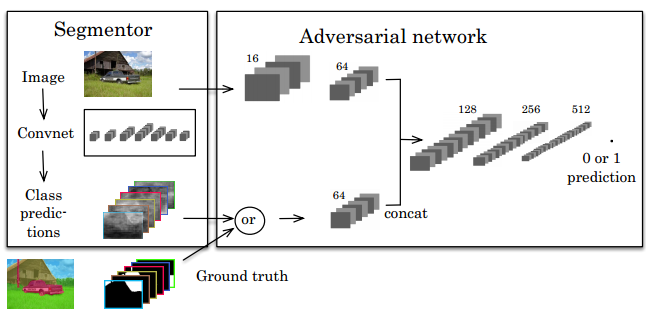
原理介绍-对抗训练
论文提出了混合损失函数,讲cross entropy和GAN的损失结合起来了:
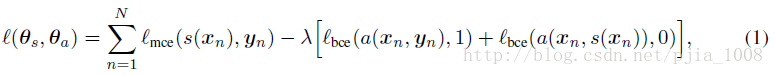
对抗训练分成两个步骤迭代,训练思想与EM算法有点像,需要找到两个参数最优相互调整,先固定一个参数,调整另一个参数,再循环迭代。
步骤1:训练对抗模型,相当于训练GAN辨别真伪的能力
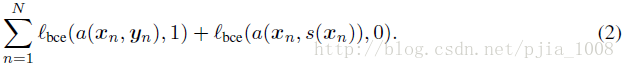
步骤2:训练分割模型,其物理意义是使得生成的概率图不仅和对应标签图相似,而且adversarial模型很难区分的开。
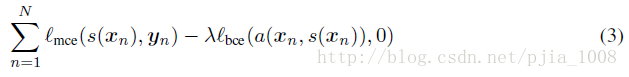
可以看到(3)式中的正则化项就是来自于(2)中的第二项,这也是论文中提到的参数共享的思想。
其他方面的应用
目前为止GAN已经没被应用到CV,NLP,Speech等领域,在工程方面,很多推荐、信息检索方面(IRGAN)的论文[8]也在尝试使用GAN。还有关于在graph-embedding方面(GraphGAN)使用GAN。
学习
看一两个实现GAN的代码,理解一下GAN是如何应用的。
- github地址:https://github.com/openai/improved-gan,文献[2]
- https://github.com/oyam/Semantic-Segmentation-using-Adversarial-Networks,文献[3]
- https://github.com/geek-ai/irgan, 文献[8]
参考文献
[1] Generative Adversarial Nets, Ian J. Goodfellow.
[2] Improved Techniques for Training GANs. Tim Salimans, Ian Goodfellow.
[3] Semantic Segmentation using Adversarial Networks. Pauline Luc.
[4] http://blog.csdn.net/shenxiaolu1984/article/details/75736407.
[5] http://blog.csdn.net/diligent_321/article/details/55224631.
[6] http://blog.csdn.net/pjia_1008/article/details/77096618.
[7] http://blog.geohey.com/ji-suan-ji-shi-jue-zhi-yu-yi-fen-ge/.
[8] IRGAN: A Minimax Game for Unifying Generative and Discriminative Information Retrieval Models